Map理解
看下Map的原理,其实也是件有趣的事情


简述
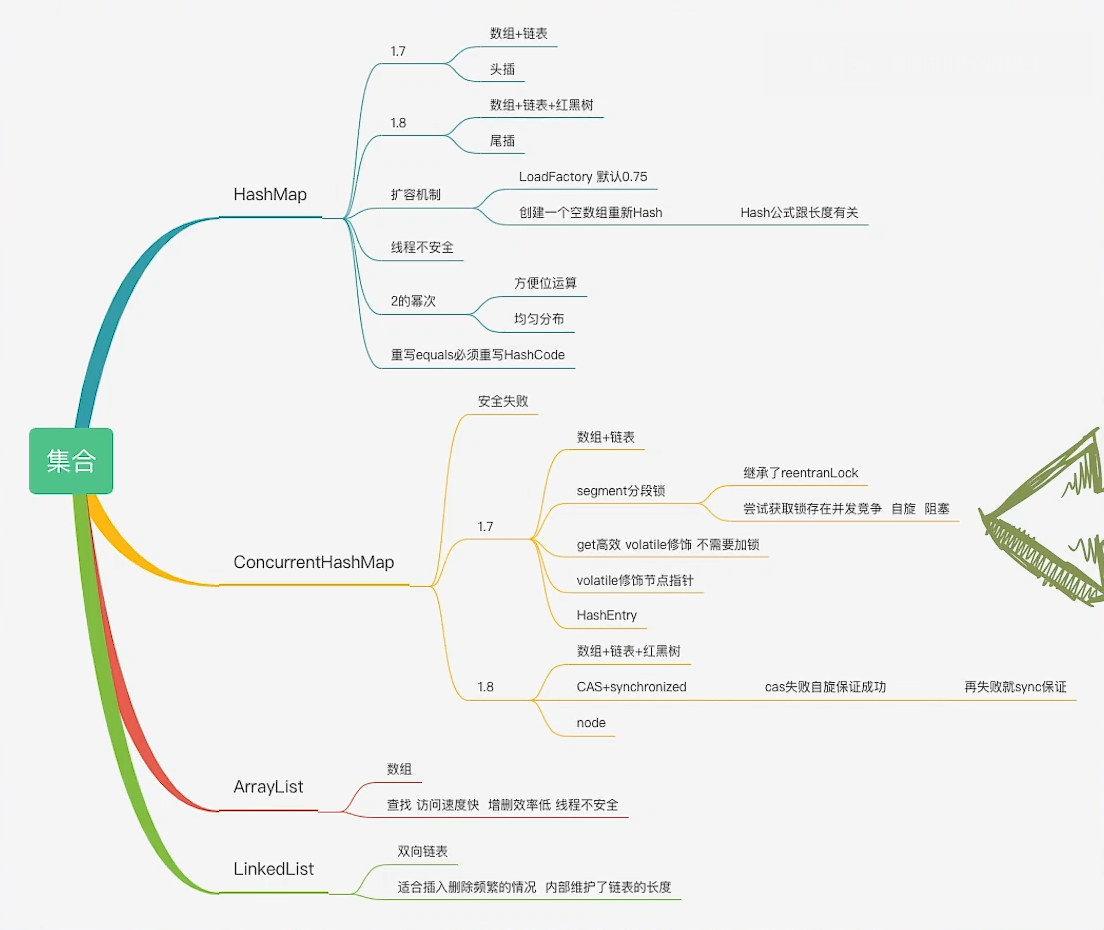
Map是个接口,实现分别有HashMap、LinkedHashMap、TreeMap、ConcurrentHashMap
- 哈希表是数组+链表
- HashMap由数组+链表/红黑树
- LinkedHaspMap由数组+链表+双向链表
- TreeMap由红黑树
- ConCurrentHashMap有数组+链表/红黑树
创建一个hashMap
- HashMap默认大小为16,负载因子为0.75。
- 大小只能是2次幂,具体实现可在tableSizeFor看到。
- 负载因子的大小决定哈希表的扩容和哈希冲突
💡
负载因子调高,hash冲突概率可能会增加
把元素put进map
把元素放进map时,先使用hash查询出元素所在位置,使用位运算来代替取模(更高效算出位置)。
每次put元素时,都会检查size大小。
传递的key怎么计算哈希值?先算出正常哈希值,然后高16位做异或运算(增加随机性,减少碰撞可能性)
- 先对key做hash计算,获取所在的index
- 如果没碰撞,则放入数组;如果碰撞,判断当前数据结构是链表还是红黑树
- 如果key相同,替换值,判断哈希表是否已满,如果满了,则扩容
从map中get一个元素
- 通过hash计算key所在index,判断是否有hash冲突
- 如果没有冲突,直接返回;如发生冲突,需判断当前数据结构再取出
HashMap中如何判断一个元素是否相同
- 先比较hashCode,然后用==运算符和equals()来判断是否相等
- hashCode相同,说明冲突,hashCode和运算符都相等,说明元素是同一个
HashMap什么时候会使用红黑树
- 当数组大小大于64且链表大小小于8时;当红黑树大小为6时,会退化成链表
💡
链表查询时间复杂度O(N),插入时间复杂度O(1),红黑树查询和插入时间复杂度O(logN)
1.7
使用头插法插入数据。put元素,在resize的时候,调用了transfer方法,把里面一些Entry进行一个rehash,可能会造成链表循环,在下一个get时候出现死循环的情况。没有加锁,多线程下有可能线程不安全。(补充:导致循环链表是因为头插法每次resize,会进行链表反转,多线程环境下会导致循环指针)
数据结构只使用数组+链表,数据节点是一个Entry类,一个内部类。
1.8
数组+链表/红黑树,尾插法,原来的Entry节点变成Node节点。扩容机制,capacity在初始化hashMap的时候,默认容量是16,负载因子是0.75,计算初threshold是他的阈值。put的时候先判断当前size是否大于这个阈值。如果大于,会新创建一个两倍大小扩容,将原来的Entry进行resize的过程。
采用尾插法,没有改变原来的插入顺序,不会出现链表循环的情况。
如何保证线程安全?
使用ConcurrentHashMap
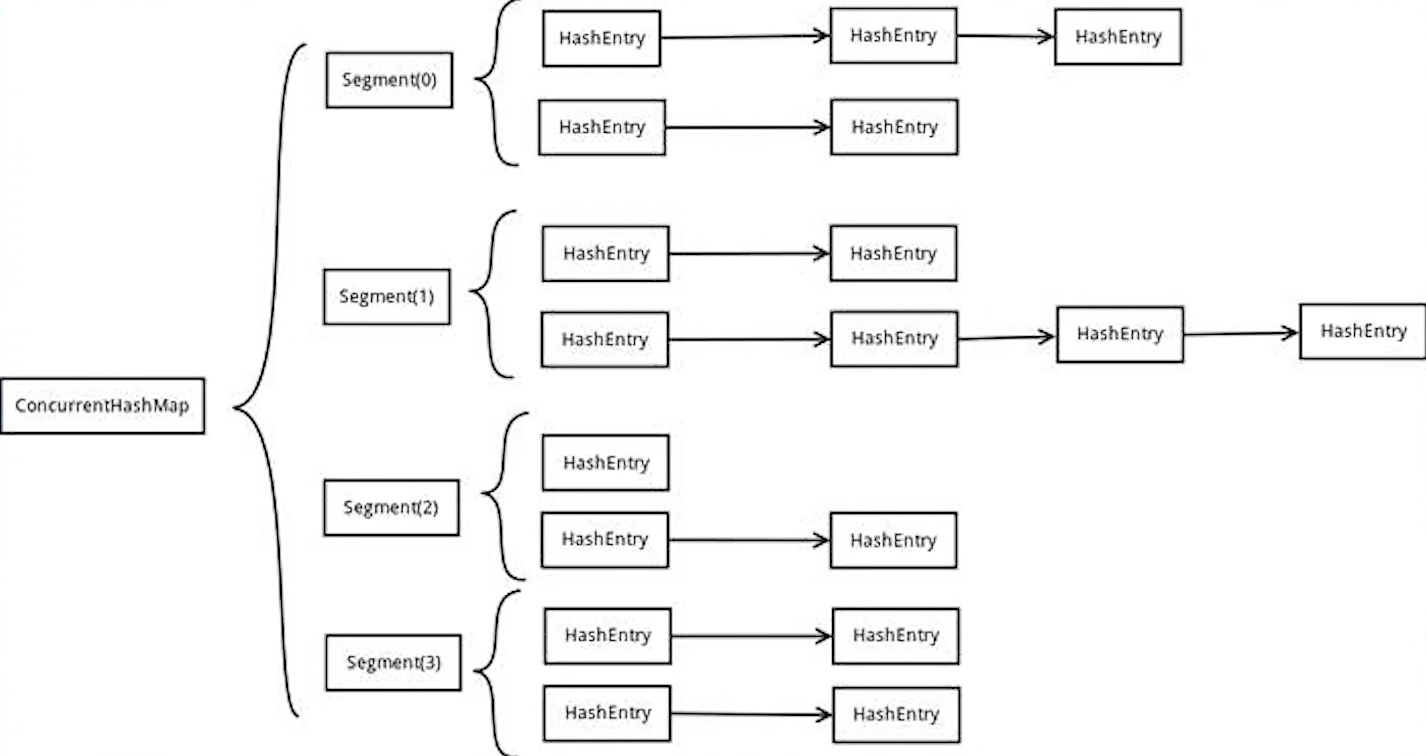
- 为什么不使用HashTable?
HashTable是对方法进行Synchronized,加了对象锁。ConcurrentHashMap只会锁住目前获取到Entry所在节点的值,使用CAS Synchronized,JDK1.6以后对sync做了优化锁升级的过程。
锁升级过程
(最开始是无锁状态,先判断再升级)最开始的时候锁是支持偏向锁,当前获取锁资源的这个线程,会优先让它再去获取这个锁,如果他没有获取到锁,就升级成轻量级的锁(CAS轻量锁),乐观锁是有比较并交换的过程。CAS在没有设置成功的时候,会进行一个自旋,自旋到一定的次数后会升级成Synchronized重量锁,保证性能问题HashMap 介绍
hashmap支持null键值
jdk1.8前hashmap由数组加链表组成,数组是hashmap主体,链表是为了解决hash冲突。
jdk1.8之后引入了红黑树,当链表长度大于阈值(默认为8)并且当前数组长度大于64时,此时索引位置上的数组会转化为红黑树,但是如果阈值大于8,但是数组长度小于64,并不会转换成红黑树,而是进行数组扩容。(阈值大于8且长度大于64后转红黑树效率会变快)
HashMap存储逻辑
根据key值的hashCode()值进行无符号右移(>>>),按位异或(^),按位与(&)计算出索引。如果索引处已经有值,判断两个key的hashCode()是否相等,不相等则在该索引创建链表向下存储,如果hash值相等,则发生了hash碰撞,需要判断两个key的值是否相同如果相同则覆盖,不相同则顺着链表依次向下执行以上逻辑。
1.HashMap中Hash函数怎么实现的?
对key的hashCode值做hash操作,无符号右移然后做异或运算。
还有伪随机数法和取余数法,位运算是效率最高的
2.HashCode值相等怎么办?
判断两个key的值是否相等,如果相等则覆盖value,否则顺着链表向下依次对比,如果链表长度超过8且数组长度超过64则转为红黑树
3.HashMap扩容逻辑?
当存储的元素个数超出临界值时进行扩容,长度为原数组的2倍,并且复制原来的数组。
4.为什么要添加红黑树?
当存储数据量较大时,可能一个索引下存储了很多个数据,这些数据都在一个链表上,此时读取数据的时间复杂度是O(n),而如果转换成红黑树,那么时间复杂度为O(logn),读取效率变高。当红黑树内元素被删除的少于6位后,会重新变成链表。
5.为什么HashMap的长度为啥必须是2的n次幂
为了减少hash碰撞。为了让hashMap存储高效,最好能把数据比较均匀的存放在每一个索引上,而比较好的办法就是取余,hash%length,而hash%length==hash&(length-1)(前提是length=2的n次幂)
6.怎么做到长度自动变为2的n次幂的?
数组长度一定是2的n次幂,如果指定长度不是2的n次幂,则通过无符号右移,按位或运算,算出大于指定值的最小的2的n次幂
7.为什么当链表长度超过8才转红黑树?
因为在随机哈希值的概率下,理论上随机到每个桶的概率是满足泊松分布的。泊松分布理论中,一个链表长度达到8的概率为0.00000006,而又因为红黑树虽然查询效率高,但是占用的空间是链表的2倍,所以其实java还是不太希望链表的长度转化为红黑树的,因此阈值设置为8 。
8.为什么链表长度<=6之后变回链表?
变回链表是因为链表长度小于6的时候和红黑树的查询速度差距是很小的,而设置为6的原因是防止频繁切换链表和红黑树,比如如果小于8就转换,则如果红黑树删除一个元素变为7,转换为链表,如果这时又添加了一个元素,则又变为红黑树,影响性能,因此中间长度为7做过度。
HashMap比较重要的常量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //默认数组长度static final int MAXIMUM_CAPACITY = 1 << 30; //最大数组长度static final float DEFAULT_LOAD_FACTOR = 0.75f; //负载因子static final int TREEIFY_THRESHOLD = 8; //链表转换为红黑树的阈值static final int UNTREEIFY_THRESHOLD = 6; //红黑树转换为链表的阈值static final int MIN_TREEIFY_CAPACITY = 64; //数组长度大于这个值链表才 (要同时满足MIN_TREEIFY_CAPACITY和TREEIFY_THRESHOLD)int threshold; //边界值,当数组内的元素大于该值就扩容,=数组长度*负载因子
hashmap链表里面存放 - CSDN
csdn已为您找到关于hashmap链表里面存放相关内容,包含hashmap链表里面存放相关文档代码介绍、相关教程视频课程,以及相关hashmap链表里面存放问答内容。为您解决当下相关问题,如果想了解更详细hashmap链表里面存放内容,请点击详情链接进行了解,或者注册账号与客服人员联系给您提供相关内容的帮助,以下是为您准备的相关内容。